


SBP and Zameen: SBP is better off taking decisions based on vibes
What are the data scientists at SBP doing?

A couple of days ago I was thinking that it has been a while since I wrote about anything related to SBP and wondering if it is time to call it quits on this substack? Today, SBP gave me a gift.


It behooves SBP to at least look at data before signing an MoU. This post will mostly comprise of tweets to get across the point that SBP is either willingly or unwillingly getting deceived here.
I scraped Zameen website in June 2022. I will give the python code at the end of this post in case you want to scrape the data so that you can reach your own conclusions. This was the page 1 of the data.

These are first 20 or so listings of more than 45k listings in Karachi at the time. The thing is that none of this data is genuine transaction data.


This is just listing information. Zameen doesn’t even verify if the property exists. Most of the time, brokers use it to bait customers.


Zameen website had 45K listings in Karachi alone. There is no way to know which of them is genuine. How is SBP going to use this unreliable data to decide on monetary policy? The only thing one can do is to note what area or size of property is getting listed.

Moreover, Zameen pushes a lot of shady projects.



The surprising aspect is that some people in SBP know that Zameen is shady but they still chose to move ahead with them.
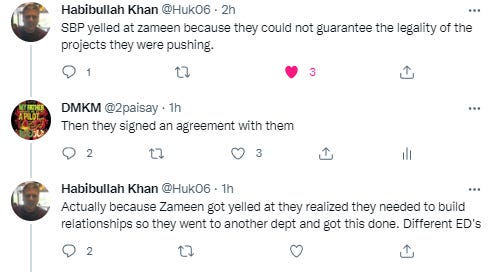
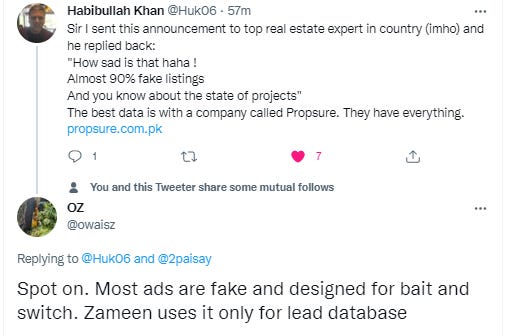
All of this begs the question, didn’t the Deputy Governor SBP Murtaza Syed not have anyone do due diligence on Zameen sponsors and the data on their platform before signing this MoU.
Below is the 20+ line code that I used to scrape data. I am sure there are much more qualified persons at SBP whose bread and butter is data analysis. Murtaza Syed should have at least ask them to test the quality of data. Now SBP will be using this fake data (if we can call it data) to decide on future monetary policy.
Python Code for scraping data off Zameen dot com
filelist = []
# This will store the URL of each listing
cities = ["Lahore-1-","Karachi-2-","Islamabad-3-"]
#You can create your own list or add to this for other cities.
city = cities[1]
#Karachi. Select 0,1,2 for Lahore, Karachi, Islamabad respectively.
# Each page has 25 listings. There are thousands of listings on Zameen for each city.
# For Karachi, there are 45,367 listings which translated into 45,367/25 = 1814 pages.
num_of_pages = 10
# As it takes a while to run, this will do 10 pages. You can do as many pages as you want.
for pgnum in range(num_of_pages):
url = "https://www.zameen.com/Homes/"+city+str(pgnum+1)+".html?sort=price_desc/"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
properties = soup.find_all("a", class_="_7ac32433")
for listing in properties:
property_url = "https://www.zameen.com/"+ (listing.get("href"))
filelist.append(property_url)
#There are quite a few duplicate listings when running the above code. To remove duplicates
filelist = list(dict.fromkeys(filelist))
# convert into list of lists as easier to append data and export to excel
filelist = list(map(lambda el:[el], filelist))
# Now get property data from each property page
for counter in range(len(filelist)):
url = filelist[counter][0]
soup = BeautifulSoup(requests.get(url).content, "lxml")
try: # In case some data is missing or its format causes an error
prop_type=soup.find("span",{"aria-label":"Type", "class":"_812aa185"}).text
price = soup.find("span",{"aria-label":"Price", "class":"_812aa185"}).text
address = soup.find("span",{"aria-label":"Location", "class":"_812aa185"}).text
baths=soup.find("span",{"aria-label":"Baths", "class":"_812aa185"}).text
area=soup.find("span",{"aria-label":"Area", "class":"_812aa185"}).text[:-7].replace(",","")
purpose = soup.find("span",{"aria-label":"Purpose", "class":"_812aa185"}).text
beds = soup.find("span",{"aria-label":"Beds", "class":"_812aa185"}).text
date = soup.find("span",{"aria-label":"Creation date", "class":"_812aa185"}).text
filelist[counter].extend([prop_type,price,address,baths,area,purpose,beds,date])
except:
filelist[counter].extend(["N/A","N/A","N/A","N/A","N/A","N/A","N/A","N/A"])
#exporting to CSV
column_headings = ["URL", "Property Type","Price","Address","Baths","Area in Sq Yds","Purpose","Beds","Date created"]
import csv
with open ("zameen.csv","w",encoding="utf-8", newline="") as f:
write = csv.writer(f)
write.writerow(column_headings)
write.writerows(filelist)